In the first experiment, our agent was given a breeding program with a fixed budget; The same number of offspring were produced each generation. In reality, the breeder can allocate resources unevenly across the selection cycles. The simplest way to allocate budget is to increase the number of grown individuals, giving them more shuffled genomes and potentially higher trait scores.
This presents an interesting extension for our breeder agent. We will now give it a starting budget and each cycle it can decide how much of the current budget to spend on the given cycle. The goal will be to train an agent which can succesfully match the baseline given this action space and learn where it allocates larger portions of the budget.
In this case, we have 2 variables, so will produce a heatmap where the x axis is the selection intensity (% of population to use as parents) and the y axis is the budget allocation (% of remaining budget to spend on the current cycle).
We can see a clear landscape of optimal values peaking at low action values for both selection intensity and budget allocation per cycle. These actions correspond to selecting the top ~10% of the individuals as parents, and spending ~10% of the remaining budget each cycle. This represents the baseline since this heatmap shows the result for fixed actions. The agent will be able to dynamically change these values for each round of selection.

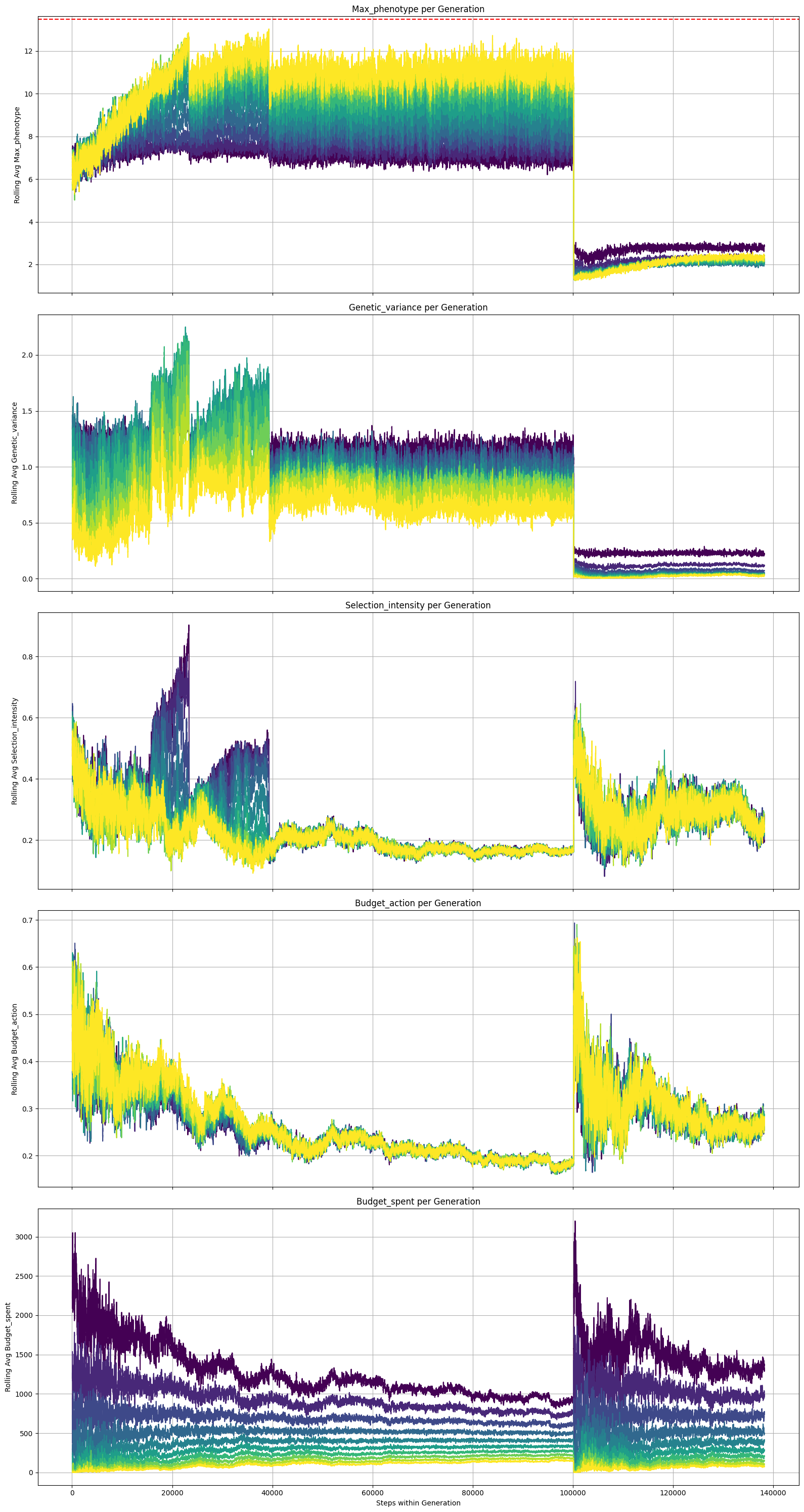
Generally, the agent is able to learn strong solutions, here we have 3 sets of training logs for breeding programs which run for a total of 5/10/100 rounds of selection. The agent will have a budget of 1000 units where each unit equals one additional offspring for the cycle it is spent. The agent’s score is determined by the max phenotype of the final generation. This budget is fixed across all 3 durations.
Purple: first round of selection Yellow: final round of selection
Left: 5 rounds of selection Middle: 10 rounds of selection Right : 20 rounds of selection
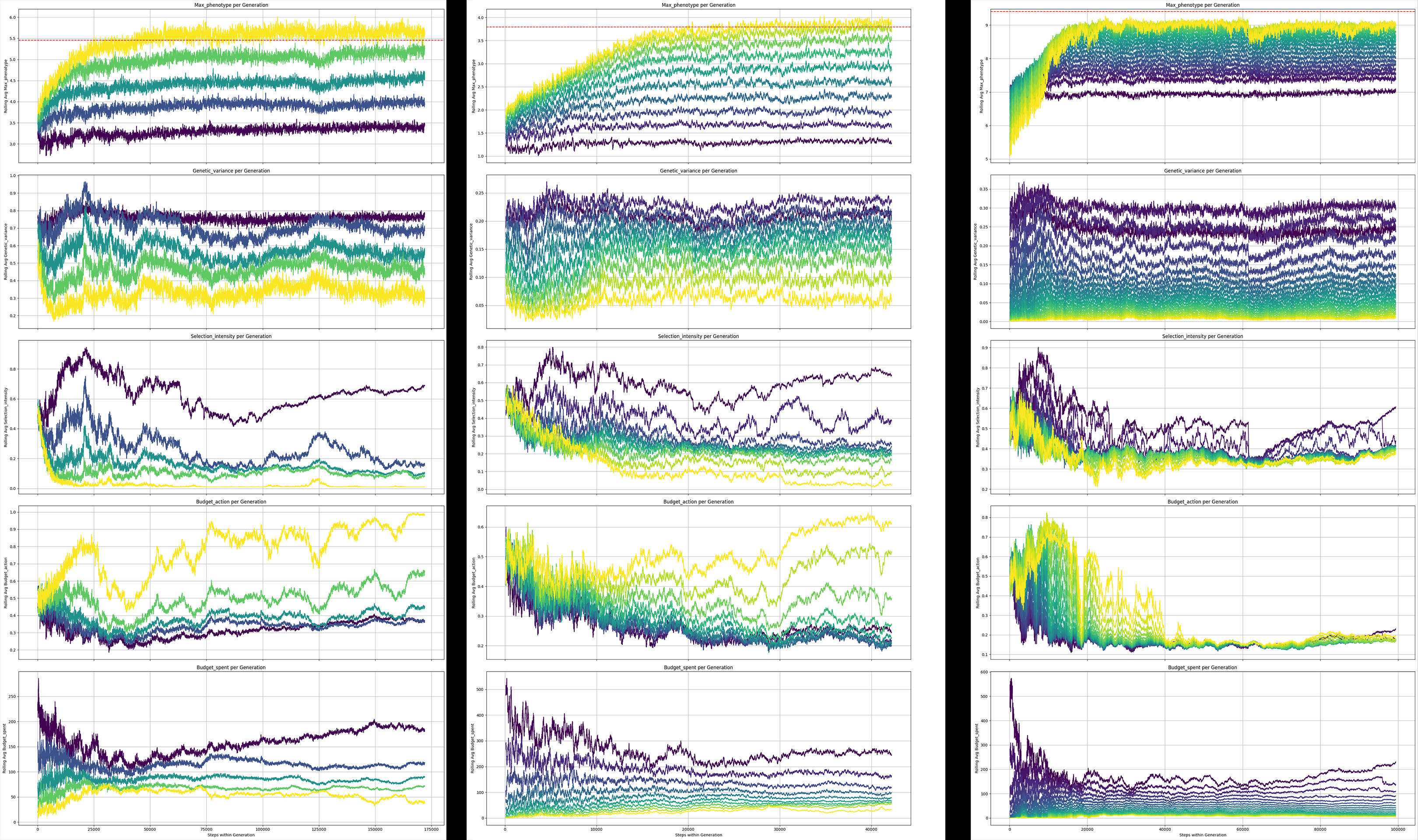
The agent again discovers a good solution which differs from our constant baseline method for the 5/10 cycle programs using dynamic values for the action values for selection intensity and budget allotement depending on the cycle of the program. A good signal training is close to complete may be when the final cycle’s budget_action reaches 1.0 which means the agent effectively spends all its remaining money. This is observed in the logs for the 5 cycle program but not yet 10.
On the other hand the 20 cycle program the agent does not quite match the baseline. We can see that the selection intesity and budget allotments become relatively fixed, converging on a suboptimal solution. It is well known that reinforcement algorithms are relatively unstable and sensitive to their settings. Fixes for this behavior may include tweaking the neural network the agent is using or the hyperparameters for the learning/training algorithms, or reframing the logic for the agents actions and inputs.
Curriculum learning is a common approach to dealing with machine learning tasks that are complex. Given that the agent starts with no knowledge, this technique aims to make the game begin as simple as possible and over time become more like the intended scenario. In this context, it means we would start training the agent to make a single round of selection at a time; once it learns to use all its budget, and use a low selection intensity (a strong heuristic for a single year scenario), then we would extend the breeding program to 2 years, then once it’s figured out a good strategy, extend it to 3 years and so on. This would likely stablize training and avoid training collapses as seen in the 20 year (above) and 100 year (below) simulations.
Even longer time horizons - 100 cycles
Carrying a single, isolated population for 100 cycles of selection is unrealistic, however we can simulate it anyways. The effects of instability are much stronger in this case as seen in the training logs below. Budget 10k.